

You spend an hour explaining your project architecture, your coding preferences, your deployment constraints. The AI nails the task. You close the tab. You come back the next morning and it has absolutely no idea who you are.
This isn't a quirk. It's an architectural problem baked into how large language models work. LLMs are stateless by design. When a session ends, everything evaporates. Your preferences, your project history, the three hours you spent getting it to understand your authentication schema. Gone.
The industry has thrown two solutions at this problem for years. The first is brute force: cram more tokens into bigger context windows. Models now accept millions of tokens in a single prompt. But bigger windows are expensive to fill, and research consistently shows that models lose track of critical details buried deep in massive prompts. The "lost in the middle" problem is real, and throwing more context at it doesn't fix the underlying retrieval failure.
The second approach is RAG with vector databases. Store your conversations as embeddings, retrieve semantically similar chunks when you need them. This works for basic recall. But flat vector search struggles with temporal reasoning ("what did we decide about auth last month, not the conversation from six months ago?"), multi-hop logic, and the kind of nuanced preference tracking that makes an AI assistant actually useful over weeks and months of collaboration.
Into this gap walks one of the strangest open-source launches of 2026.
A Hollywood Actress, a Bitcoin CEO, and a Memory Palace Walk Into GitHub
On April 5, 2026, Milla Jovovich pushed a Python repository to GitHub under her own account. Yes, that Milla Jovovich. The actress from The Fifth Element and the Resident Evil franchise.
The repository was called MemPalace. Within 48 hours, it had over 7,000 stars. As I write this, it's past 22,000. The developer community collectively did a double-take, and the internet responded the way the internet does. Someone pointed out the missed opportunity to call it "Resident Eval." A community note on X claimed Jovovich's involvement was "conceptual or promotional." An AI commentator dug into the commit history and accused the whole thing of being a paid operation.

Here's what actually happened, stripped of the drama. Jovovich spent months working on a gaming project and got deeply frustrated with AI's inability to remember her world-building details across sessions. She researched mnemonic techniques, landed on the ancient Greek "Method of Loci" (the memory palace technique orators used to memorize massive speeches), and conceptualized a system built around that spatial metaphor. Her technical co-founder, Ben Sigman (CEO of Libre Labs, a Bitcoin lending platform), engineered the implementation and released it as an MIT-licensed open-source project.
The origin story is unconventional. But the problem MemPalace tries to solve is real, and the approach is genuinely interesting. So let's separate the hype from the architecture and figure out what's actually useful here.
The Core Idea: Stop Letting AI Decide What to Remember
Most AI memory systems work the same way. When you finish a conversation, the system prompts an LLM to read the interaction, extract key facts, and store structured summaries. Mem0 does this. Zep does this. Letta does this (though it lets the agent itself manage the process).
The problem? The AI decides what matters. It might extract "user prefers PostgreSQL" and throw away the entire conversation where you explained why you prefer PostgreSQL, what alternatives you considered, and the specific tradeoffs that drove the decision. That context is gone forever. And the next time you need your AI to make a nuanced recommendation, it has a fact without any of the reasoning behind it.
MemPalace takes the opposite approach: store everything verbatim and make it findable.
No LLM touches your data during the write phase. Raw conversations go straight into a local ChromaDB vector database, preserving every word. The intelligence isn't in what gets stored. It's in how the stored data gets organized and retrieved.
This is a genuinely contrarian position in the current market, and it comes with real tradeoffs I'll get into. But the philosophy deserves attention because MemPalace's own benchmarks reveal something the AI memory industry has been quietly ignoring: raw, uncompressed text paired with decent embeddings often outperforms carefully curated LLM summaries on retrieval tasks. The reason is straightforward. When you summarize, you lose the granular details that specific questions need to match against.
How the Memory Palace Actually Works
The "palace" metaphor isn't just branding. It maps directly onto the system's metadata schema, and understanding it is the key to using MemPalace effectively.
Ancient Greek orators memorized speeches by visualizing a building and placing specific ideas in specific rooms. To recall an idea, they'd mentally walk through the building and find it by location. MemPalace applies this same principle to vector database metadata, creating four levels of spatial hierarchy.
Wings are the top level. Think of them as entire buildings dedicated to a broad domain. You might have a wing for a specific project ("orion_project"), a wing for personal notes ("emotions"), or a wing for a client ("acme_corp"). Wings prevent cross-contamination. Your AI debugging authentication code in the "orion_project" wing won't accidentally pull up your personal diary entries, even if both contain overlapping vocabulary.
Rooms sit inside Wings. They represent tightly focused areas. Inside your "orion_project" wing, you might have rooms for "authentication," "database," and "deployment." All architectural decisions, bugs, and discussions related to auth get clustered in that one room.
Halls are metadata labels that categorize the type of memory. Is this a factual assertion? A temporal event? A user preference? The system classifies content into five categories: Travel, Work, Health, Relationships, and General.
Drawers are the atomic units. Each drawer contains a vectorized chunk of raw text with numeric weights for importance and emotional resonance.
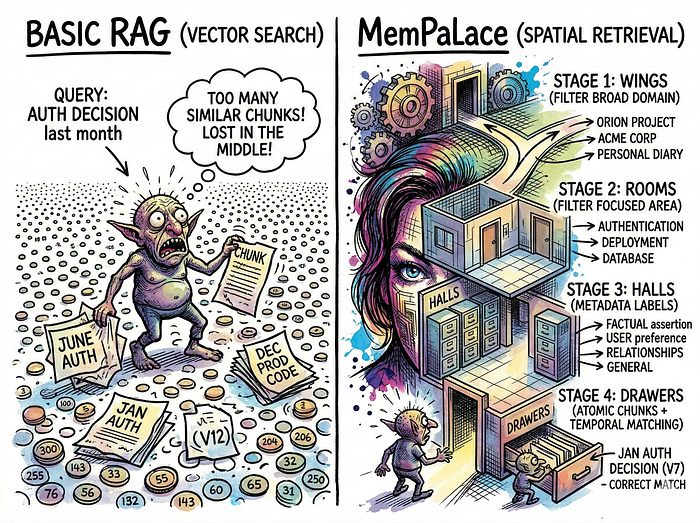
The spatial hierarchy acts as a set of pre-filters during retrieval. Instead of searching your entire vector database for "authentication decisions," the system narrows the search to the specific wing and room first, then runs semantic similarity within that constrained space. It's a simple idea, but it meaningfully improves retrieval accuracy by eliminating irrelevant results that happen to be semantically similar.
The system also builds "Tunnels," which are cross-references created automatically when the same room name appears in different wings. If you have an "authentication" room in both "orion_project" and "nova_project," the tunnel lets your AI traverse between them, comparing how you approached the same problem in different contexts. That's a genuinely useful capability for long-term development work.
The Token Economy: Why Startup Cost Matters
One of MemPalace's strongest design decisions is its 4-layer memory stack. This is where the system delivers real, practical value for anyone building agents.
Layer 0 is your identity file. A small text file (~50–100 tokens) containing your core directives, voice style, and behavioral boundaries. It loads into every session, every time.
Layer 1 loads the top 15 most important memories across your entire palace, sorted by importance and emotional weight. This costs roughly 500–800 tokens.
Layer 2 loads context specific to the current conversation topic. If you start talking about authentication, it pulls memories from the relevant wing and room. Another 200–500 tokens.
Layer 3 is the deep search. Full semantic similarity across everything. Only triggered when explicitly needed.
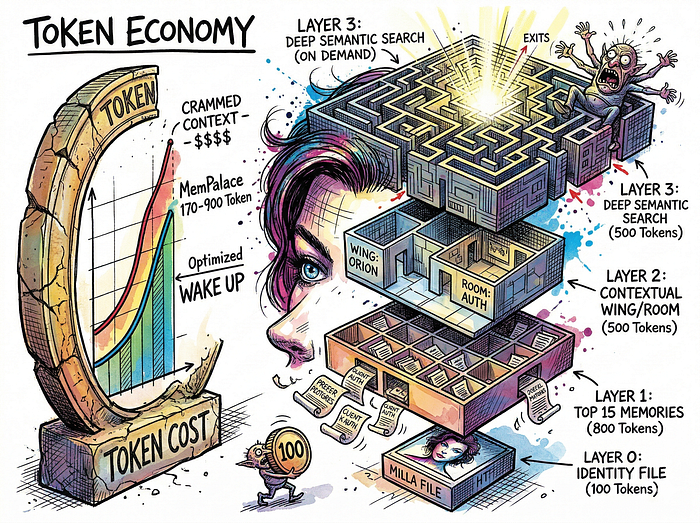
The result: your agent can wake up with full operational context for about 170–900 tokens. Compare that to stuffing your entire conversation history into the prompt. For solo developers paying per-token API costs, this is the difference between a usable system and one that burns through your budget before the AI generates a single response.
Letta uses a similar tiered approach (inspired by computer memory hierarchies: RAM, cache, cold storage), but Letta requires LLM calls to manage the swapping. MemPalace uses deterministic metadata triggers. Faster, cheaper, less accurate for edge cases. A tradeoff worth understanding.
The Parts That Don't Work as Advertised
And now the part most blog posts skip. MemPalace has real problems, and some of them are serious enough that you should know about them before you invest time in the setup.
The "lossless" compression claim is false. MemPalace includes a proprietary compression dialect called AAAK, marketed as achieving "30x compression, zero information loss." Independent analysis of the codebase shows this is flatly untrue. The compression function truncates content to a maximum of three entities, three topic words, three emotion codes, and a single sentence quote capped at 55 characters. The decode() function can't reconstruct the original text. It just parses the abbreviated format back into a dictionary. MemPalace's own benchmarks show that AAAK-compressed text scores 84.2% on retrieval tasks compared to 96.6% for raw text. That's a 12.4 percentage point drop. By definition, lossless compression cannot reduce retrieval accuracy. AAAK is lossy summarization, not compression. The maintainers have acknowledged some of these issues, including that their token count examples used a rough heuristic instead of an actual tokenizer.
The 100% benchmark score is manufactured. The 96.6% baseline on LongMemEval is real and impressive. But it's attributable to standard ChromaDB vector search against raw text, not to MemPalace's spatial architecture specifically. The jump from 96.6% to 100% happened through targeted hardcoding. The developers manually inspected the three questions the system failed, then wrote regex patterns specifically designed to pass those exact queries. One boost targeted a question about someone named "Rachel." Another searched for the exact phrase "when I was in high school." The project's own documentation admits this on line 461 of BENCHMARKS.md: "This is teaching to the test." Ben Sigman has acknowledged publicly that the system's superiority is "not proven."
Contradiction detection doesn't exist. The marketing claims the system "catches wrong names, wrong pronouns, wrong ages before you ever see them." A line-by-line code review shows the word "contradict" doesn't appear anywhere in the knowledge graph module. The only deduplication is an exact-match filter preventing identical triples from being inserted twice. If your agent stores "Age: 30" on Tuesday and "Age: 45" on Wednesday, both facts stay in the database indefinitely.
The knowledge graph is rudimentary. MemPalace uses SQLite for its knowledge graph. It works for basic entity relationships and simple temporal queries. But it lacks entity resolution (it can't figure out that "Alice," "Alice S.," and "A. Smith" are the same person), community detection, or any of the sophisticated graph algorithms that Neo4j-backed systems like Zep/Graphiti provide.
These aren't minor issues. They represent a significant gap between marketing and reality. Independent reviewers on GitHub have noted that MemPalace is "the only system we've reviewed with multiple outright false claims in the README."
So Why Should You Care?
Because underneath the overblown marketing, MemPalace gets several things right that matter for practical use.
It runs entirely locally. Your data never leaves your machine. No API calls during storage. No cloud dependencies. For anyone working with proprietary code, sensitive client data, or just wanting privacy, this is a genuine advantage over Mem0's managed cloud (which scales up to $249/month) or Zep's infrastructure requirements.
It costs nothing. The entire system runs on ChromaDB and PyYAML. Two dependencies. No API keys needed for storage and basic retrieval. For solo developers and hobbyists, this removes the biggest barrier to experimenting with persistent agent memory.
The spatial metaphor actually helps. Not because it's a breakthrough in computer science, but because it gives you an intuitive way to think about organizing your AI's memory. Wings, rooms, halls, and drawers map naturally to how most people already think about their projects and knowledge domains. And the metadata filtering it enables is a legitimate improvement over flat vector search.
The MCP integration is excellent. 19 tools available out of the box for Claude, ChatGPT, and Cursor. The setup is a single terminal command.
The 96.6% baseline is genuinely impressive. Strip away the inflated 100% claim and you still have a system that scores higher than Mem0 (around 49%) and Zep (around 64%) on LongMemEval. The insight that raw verbatim text with good embeddings beats LLM-extracted summaries is a finding the entire industry should pay attention to.
Where MemPalace Fits in the 2026 Memory Landscape
The AI agent memory market is fragmented, and each tool serves a different use case. Here's an honest positioning based on my research.
Mem0 is the industry standard for managed memory. Best if you want drop-in personalization, don't mind cloud dependency, and have budget for the Pro tier ($249/month) to access graph features. It has the largest ecosystem (50,000+ developers) and the broadest integration support.
Zep/Graphiti is the choice for temporal reasoning. If your agents need to track how facts change over time with precision ("What was our deployment strategy in January vs. March?"), Zep's Neo4j-backed temporal knowledge graph is purpose-built for this. But it requires heavier infrastructure and costs $25/month minimum.
Letta is the most architecturally interesting option. Its OS-inspired approach (agents manage their own memory like an operating system manages RAM) is genuinely innovative. But adopting Letta means adopting an entire agent runtime, not just a memory layer.
MemPalace fills a specific gap: the solo developer or small team that wants persistent memory with zero cloud costs, complete data privacy, and no infrastructure overhead. It's the lightest-weight option, and the spatial organization makes it surprisingly intuitive to manage. But it's not a replacement for enterprise-grade systems, and you need to go in with clear eyes about its limitations.
Getting Started: A Practical Setup Guide
Enough theory. Here's how to actually put MemPalace to work.
Step 1: Install
pip install mempalaceThat's it. Two dependencies (chromadb and pyyaml) install automatically.
Step 2: Create Your Identity File
This is Layer 0, the foundation of every session. Create the file at ~/.mempalace/identity.txt:
Name: [Your name]
Role: Senior backend developer
Primary languages: Python, TypeScript
Coding style: Prefer explicit over implicit, type everything,
test first
Communication: Direct, skip the pleasantries, give me the tradeoffs
Current focus: Migrating auth system from JWT to session-based tokensKeep this tight. 50–100 tokens maximum. Think of it as the absolute minimum context your AI needs to be useful. You're not writing a biography. You're writing a boot sequence.
Step 3: Mine Your Existing Conversations
If you have exported chat logs or project files, feed them in:
mempalace mine ~/chats/project-orion/ --mode convos --wing orion_project
mempalace mine ~/code/orion/src/ --mode projects --wing orion_projectThe miner automatically processes 20 file types (.py, .js, .ts, .md, .txt, and more), ignores build directories and node_modules, and assigns files to rooms based on a 4-step cascade: directory path matching, filename analysis, keyword frequency scoring, and fallback to a general room.
A word of caution here: the deterministic assignment isn't always perfect. Files with ambiguous content might land in the wrong room. Check the results and manually reorganize anything that looks off. The system won't autocorrect misclassifications.
Step 4: Connect to Your AI via MCP
For Claude Code (other MCP clients like Cursor and OpenCode use their own config files):
claude mcp add mempalace -- python -m mempalace.mcp_serverFor Cursor, add to your MCP config. The 19 available tools include mempalace_search, mempalace_store, and specialized tools for knowledge graph queries.
Once connected, your AI can autonomously search your memory palace during conversations. Ask it about decisions you made weeks ago, and it'll pull the relevant context from the right wing and room without you needing to re-explain anything.
Step 5: Structure Your Palace Intentionally
This is where most people either over-engineer or under-engineer. Here's a practical starting structure:
Create one wing per major project or life domain. If you're a freelance developer with three clients, that's three wings plus maybe a "personal" wing and a "learning" wing.
Within each project wing, let the rooms emerge from your actual work. Don't pre-create 20 empty rooms. Start with broad rooms ("backend," "frontend," "devops") and let the miner populate them. Split rooms when they get too large or cover too many distinct topics.
The default halls (Work, Health, Relationships, Travel, General) will handle most categorization automatically. Don't fight the defaults unless you have a specific reason to.
Step 6: Use the Python API for Custom Agents
If you're building your own agent outside of a GUI environment:
from mempalace.searcher import search_memories
results = search_memories(
"auth migration decisions",
palace_path="~/.mempalace/palace"
)
# Inject results into your local model's context
for memory in results:
print(f"[{memory['wing']}/{memory['room']}] {memory['text'][:200]}")This works with any local model (Llama, Mistral, whatever you're running). Pull the relevant memories, inject them into your prompt, and your local agent suddenly has weeks of context for the cost of a few hundred tokens.
What to Skip
Skip the AAAK dialect for now. The compression is lossy and measurably degrades retrieval quality. Use raw text storage unless you're genuinely running into context window limits, and even then, consider whether selective Layer 2/3 loading solves your problem first.
Skip the knowledge graph for anything mission-critical. It's useful for basic entity tracking but lacks the resolution capabilities you'd need for complex temporal reasoning. If you need "what changed between January and March," you'll get better results from Zep or even a well-structured set of dated markdown files.
Skip the benchmarks entirely as a reason to adopt. Use MemPalace because the local-first, zero-cost, spatial organization model fits your workflow. Not because of a 100% score that was hand-tuned for a static test suite.
The Bigger Lesson
MemPalace's explosive adoption reveals something about where the AI ecosystem stands right now. Developers are desperate for local, private, zero-cost memory solutions. The market has been dominated by cloud-dependent, subscription-priced tools, and there's an enormous unserved population of solo builders who just want their AI to remember what they talked about yesterday without sending their proprietary code to someone else's servers.

The spatial metaphor matters more than the code quality, at least initially. Giving people an intuitive way to think about organizing AI memory (wings, rooms, drawers) lowers the cognitive barrier to entry in a way that "configure your vector database metadata schema" never will. The fact that this repository gained over 22,000 stars despite documented false claims in its README tells you something about how hungry the community is for approachable solutions.
MemPalace isn't the best AI memory system. It's the most accessible one. And for a lot of developers, that distinction matters more than benchmark scores.
The code needs work. The marketing needs honesty. But the core idea, storing everything verbatim, organizing it spatially, and loading context in tiered layers, is sound and practically useful today. Install it, structure your palace around your actual projects, connect it via MCP, and see if your AI finally remembers who you are tomorrow morning.
That alone might be worth the 10 minutes of setup.