


There is a specific kind of humiliation that only comes from watching an AI confidently pull the wrong section from a 200-page annual report in a live demo.
I have experienced it twice.
Non Members can read here for free
The second time, I had already "fixed" the first time's problem. Better chunking strategy. Smarter overlap. More carefully tuned embedding model. The whole upgrade cycle that every RAG engineer goes through, telling themselves that the next tweak will be the one that actually works.
It wasn't.
The system retrieved a paragraph about a company's 2021 capital expenditure plan when the investor had asked about 2023 revenue projections. The two sections used similar financial language. The embeddings thought they were related. They weren't.
That's when I started questioning whether the whole approach was fundamentally broken.
The Core Lie of Vector RAG
Every RAG tutorial teaches you the same thing. Chunk your document into 500-word pieces. Embed them. When someone asks a question, find the nearest vectors. Feed the chunks to an LLM and hope for the best.
The pitch sounds elegant. Semantic search meets language generation.
Here's what nobody mentions: similarity is not relevance. Your vector database finds what is semantically close to the question, not what actually answers it. A paragraph about drug risk factors and one about drug efficacy embed near each other. But only one answers "what are the company's financial risks?"
Then there's the chunking catastrophe. Slice a 200-page legal document into 500-token windows and you destroy everything its author carefully built. The sections, the cross-references, the logical flow. What remains is a bag of fragments with no sense of where they live or how they connect.
Smarter chunking helps slightly. It never solves the core problem: you cannot recover structural context you threw away.
A human analyst would never work this way. They'd skim the table of contents, jump to the relevant section, read it with awareness of the surrounding chapter, cross-reference footnotes. Navigate the document like a document.
What if we built a RAG system that did the same thing?
PageIndex: RAG Without the Vector Database
That question is exactly what the team at VectifyAI answered when they built PageIndex.
The core insight is almost uncomfortably obvious once you hear it: instead of converting documents into vectors and searching by similarity, build a hierarchical tree index of the document — essentially a machine-readable table of contents — and then use LLM reasoning to navigate that tree to find relevant information.
No vector database. No chunking. No semantic similarity scores. Just structured indexing and intelligent navigation.
Here's what the architecture actually looks like.
How PageIndex Works: The Two-Step Process
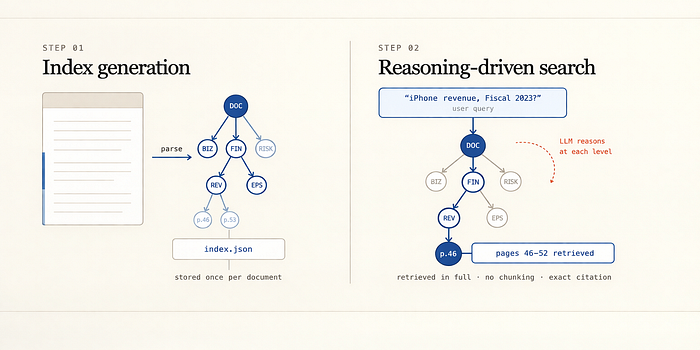
Step 1: Index Generation
When you feed a document into PageIndex, it does not fragment the document. Instead, it analyzes the document's natural structure: sections, subsections, headings, logical groupings and constructs a hierarchical index that mirrors how a human expert would organize the content.
Think of it as an automatically generated, machine-parseable table of contents. But richer. Each node in the tree doesn't just have a title, it has a summary of what that branch covers, what questions it could plausibly answer, and how it relates to sibling and parent nodes.
For a 100-page technical specification, you might get a tree three or four levels deep. The top level covers major functional areas. Drill into any node and you find sub-nodes covering increasingly specific topics. The document's logical hierarchy is preserved exactly as the author intended.
This step happens once per document, upfront, and the index gets stored. The original document content stays intact and accessible.
Step 2: Reasoning-Driven Tree Search
When a query comes in, PageIndex does not embed it and run a nearest-neighbor search. Instead, it uses an LLM to navigate the index tree.
The LLM reads the top-level nodes and reasons: "Given this question, which branch of the document is most likely to contain the answer?" It follows that branch, reads the next level of nodes, and reasons again. It continues drilling down until it has identified the specific sections of the document that are relevant.
This is the part that changes everything it retrieves those complete sections from the original document without any fragmentation, and uses them as context for answering the question.
The retrieval is explainable by design. You can see exactly which nodes in the tree the LLM traversed, and exactly which pages of the original document it landed on. There is no black-box cosine similarity score. The reasoning chain is transparent.
Getting Started: Running PageIndex Locally
Let's actually run this. The setup is minimal.
Installation
Clone the repository and install dependencies:
git clone https://github.com/VectifyAI/PageIndex.git
cd PageIndex
pip3 install --upgrade -r requirements.txtConfiguration
Create a .env file in the root directory:
CHATGPT_API_KEY=your_openai_api_key_hereRunning the Index on a PDF
Now point it at a document. Let's use a financial report as an example since that's where PageIndex excels:
python3 run_pageindex.py --pdf_path /path/to/annual_report.pdfFor markdown documents:
python3 run_pageindex.py --md_path /path/to/technical_spec.mdThat's the entire setup. No vector database to configure. No embedding model to choose. No chunking parameters to obsess over.
What the Index Actually Looks Like
When PageIndex processes a document, it generates an index structure that looks something like this (simplified):
{
"document": "Apple Inc. Annual Report 2023",
"index": {
"title": "Apple Inc. Annual Report 2023",
"summary": "Comprehensive financial and operational report covering revenue, product segments, risks, and strategic outlook",
"children": [
{
"title": "Business Overview",
"summary": "Company description, product lines, and market position",
"pages": [1, 8],
"children": [...]
},
{
"title": "Financial Results",
"summary": "Revenue, operating income, EPS, and segment performance for fiscal 2023",
"pages": [45, 72],
"children": [
{
"title": "Revenue by Product Category",
"summary": "iPhone, Mac, iPad, Wearables, and Services revenue breakdown",
"pages": [46, 52]
},
{
"title": "Geographic Revenue Distribution",
"summary": "Americas, Europe, Greater China, Japan, Rest of Asia Pacific",
"pages": [53, 58]
}
]
},
{
"title": "Risk Factors",
"summary": "Operational, market, regulatory, and competitive risks",
"pages": [89, 110]
}
]
}
}Now when an analyst asks "What was iPhone revenue in fiscal 2023?", the LLM doesn't search for semantically similar text fragments. It reads the index, reasons that "Financial Results > Revenue by Product Category" is the relevant branch, navigates there, and retrieves pages 46–52 in their entirety.
The analyst gets an answer with an exact page citation. The LLM never saw the Risk Factors section. No noise, no confusion.
Querying the Index: Under the Hood
Here's a simplified version of what the reasoning-driven retrieval looks like in code:
import json
from openai import OpenAI
client = OpenAI()
def navigate_index(query: str, index_node: dict, depth: int = 0) -> list[dict]:
"""
Recursively navigate the document index using LLM reasoning.
Returns list of relevant leaf nodes with page references.
"""
children = index_node.get("children", [])
if not children:
# Leaf node: return this section as relevant
return [index_node]
# Ask the LLM which branches are relevant to the query
children_summary = "\n".join([
f"[{i}] {child['title']}: {child['summary']}"
for i, child in enumerate(children)
])
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": (
"You are navigating a document index to find sections relevant "
"to a query. Select the index numbers of sections that are likely "
"to contain the answer. Return a JSON array of selected indices."
)
},
{
"role": "user",
"content": (
f"Query: {query}\n\n"
f"Available sections:\n{children_summary}\n\n"
f"Which sections should I look into? Return JSON array of indices only."
)
}
],
temperature=0,
response_format={"type": "json_object"}
)
selected = json.loads(response.choices[0].message.content).get("indices", [])
relevant_nodes = []
for idx in selected:
if idx # Recurse into selected branches
relevant_nodes.extend(
navigate_index(query, children[idx], depth + 1)
)
return relevant_nodes
def answer_with_pageindex(query: str, index: dict, document_pages: dict) -> str:
"""
Full PageIndex retrieval and answer generation.
"""
# Navigate the index to find relevant sections
relevant_nodes = navigate_index(query, index)
# Retrieve full text from identified pages
context_parts = []
citations = []
for node in relevant_nodes:
pages = node.get("pages", [])
if pages:
page_start, page_end = pages[0], pages[1]
for page_num in range(page_start, page_end + 1):
if page_num in document_pages:
context_parts.append(document_pages[page_num])
citations.append(f"p.{page_num}")
context = "\n\n".join(context_parts)
# Generate answer with full, unchunked context
answer_response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": (
"Answer the question based on the provided document sections. "
"Be precise. If the answer involves numbers or dates, quote them exactly."
)
},
{
"role": "user",
"content": f"Document sections:\n{context}\n\nQuestion: {query}"
}
],
temperature=0
)
answer = answer_response.choices[0].message.content
citation_str = ", ".join(set(citations))
return f"{answer}\n\n**Source:** {citation_str}"Notice what's missing from this code: embeddings, cosine similarity, vector databases, chunking logic. The whole retrieval pipeline is replaced by structured reasoning over a document index.
The FinanceBench Result That Made Me Pay Attention
Here's the benchmark that convinced me this approach is serious.
FinanceBench is a dataset of questions about real financial documents like SEC filings, annual reports, earnings calls. The questions require precise numerical answers, exact cross-references between sections, and careful reading of footnotes. It is notoriously difficult for vector-based RAG systems because financial documents are dense with similar-sounding language about different topics.
Mafin 2.5, built on PageIndex, achieved 98.7% accuracy on FinanceBench.
For context, typical vector RAG systems on similar financial document benchmarks hover around 65–80% accuracy depending on configuration. The gap is not marginal. It is the difference between a tool an investment analyst would actually trust and one that produces plausible-sounding nonsense you have to verify line by line.
The reason is structural. Financial documents are precisely the type of content where document hierarchy matters most. A consolidated balance sheet, the notes to financial statements, the MD&A section: these have clear, intentional structure that human analysts use constantly. PageIndex preserves and exploits that structure. Vector chunking destroys it.
When to Use PageIndex vs. Traditional RAG
PageIndex is not a universal replacement for vector RAG. The right choice depends heavily on what you are building.
PageIndex excels when:
- Documents have clear hierarchical structure (reports, manuals, contracts, specifications)
- Accuracy and exact citations are non-negotiable
- Your domain is specialized (finance, legal, medical, regulatory)
- Questions require cross-referencing multiple sections of a single document
- Explainability matters: you need to show why the system returned what it returned
Traditional vector RAG still makes sense when:
- You are searching across thousands of short, independent documents (e.g., support tickets, product reviews)
- Documents have no consistent structure
- You need approximate semantic search across a broad corpus
- Latency is the primary concern and you have already optimized your chunking strategy
The honest answer is that most enterprise document use cases, the ones where the AI is supposed to be actually useful, not just impressive in a demo, look a lot more like the first list than the second.
Using the PageIndex Cloud API
For production deployments without the infrastructure overhead, PageIndex offers a REST API and MCP protocol integration. The developer setup looks like this:
import requests
PAGEINDEX_API_KEY = "your_api_key"
BASE_URL = "https://api.pageindex.ai/v1"
def upload_document(file_path: str) -> str:
"""Upload a document and get back a document_id."""
with open(file_path, "rb") as f:
response = requests.post(
f"{BASE_URL}/documents",
headers={"Authorization": f"Bearer {PAGEINDEX_API_KEY}"},
files={"file": f}
)
return response.json()["document_id"]
def query_document(document_id: str, question: str) -> dict:
"""Query an indexed document and get a cited answer."""
response = requests.post(
f"{BASE_URL}/query",
headers={
"Authorization": f"Bearer {PAGEINDEX_API_KEY}",
"Content-Type": "application/json"
},
json={
"document_id": document_id,
"question": question
}
)
return response.json()
# Example usage
doc_id = upload_document("q3_earnings_report.pdf")
result = query_document(doc_id, "What was total revenue in Q3?")
print(result["answer"])
print(f"Sources: {result['citations']}")The API handles index construction automatically on upload and returns structured answers with traceable page citations on query.
The Deeper Shift This Represents
There's something philosophically important about what PageIndex is doing that goes beyond benchmark scores.
Traditional vector RAG treats documents as bags of semantically-related text fragments. It ignores the document's own organizational intelligence. Every heading, section break, and cross-reference in a well-written document is signal, the author's way of telling the reader how to navigate the content. Vector chunking throws all of that away and tries to reconstruct relevance from scratch.
PageIndex treats documents as what they actually are: structured information artifacts designed to be navigated by intelligent readers.
When a senior analyst reads an annual report, they don't read linearly from page one. They check the table of contents, jump to the segment they care about, verify a number against the notes, flip back to the MD&A. They are navigating a structured artifact. PageIndex's LLM is doing the same thing.
This is why the approach generalizes across specialized domains. A pharmaceutical trial report has a different hierarchy than a legal contract or a technical specification. But in all three cases, the author organized the document according to an internal logic that human experts exploit when reading it. PageIndex captures that logic. The retrieval step reasons through it.
What This Means If You Are Building Document AI Today
The honest reflection I had after spending time with PageIndex: I had been solving the wrong problem for years.
I was obsessing over chunking strategy when the real issue was that I was destroying document structure in the first place. I was tuning embedding models when semantic similarity was the wrong retrieval signal entirely. I was adding rerankers to fix retrieval quality when the retrieval approach itself was the bottleneck.
The RAG ecosystem spent years building sophisticated machinery to compensate for the original sin of chunking. PageIndex suggests a different path: don't chunk, don't embed, don't search by similarity. Build an index that reflects the document's actual structure and navigate it with reasoning.
This isn't the right approach for every problem. For semantic search over millions of short unstructured documents, vector search still wins. But for the large class of "ask questions about long, structured documents" problems, which is most of what enterprises actually need, the hierarchical tree approach is worth taking seriously.
I rebuilt my financial document analysis pipeline using PageIndex. The demo that embarrassed me twice? I ran it again. The investor asked about 2023 revenue projections. The system navigated to the correct section, retrieved the right pages, gave an answer with exact citations.
No more wrong year, wrong section, confident as hell.
Let's Keep Learning Together
I hope you found something valuable. If you find this post valuable:
- Show your support with a 👏 clap (or many!)
- Share it with fellow AI or Python enthusiasts who might benefit
- Let's keep learning, building, and exploring the power of AI together.
Follow me on LinkedIn for more AI engineering insights: Gaurav Shrivastav
Support the work: https://coff.ee/gaurav21s
Resources
- GitHub: github.com/VectifyAI/PageIndex — open source, self-hostable
- Chat Interface: chat.pageindex.ai — try it on your own documents immediately
- API Docs: docs.pageindex.ai — REST API and MCP integration reference