


I recently wrote 3 posts calling out Claude Code regressions.
- Claude Code Insane Nerf. AMD Noticed (Here's How You Fix It).
- Opus 4.7 Is The Worst Release Anthropic Has Ever Shipped.
- Claude Code Has A Big Problem. What You Can Do.
Not a Medium member? Read for free by clicking here.
People told me I was overreacting, that it was a skill issue (this gaslighting upset me the most). I was even told personally to "get better at prompting dude".
Anthropic just published a postmortem confirming everything that happened.
There was a reason my posts had so many claps, not because I was being dramatic, because we were facing these issues together.
Now we have confirmation from Anthropic.
What The Postmortem Actually Said
On April 23rd, Anthropic published "An update on recent Claude Code quality reports".
This postmortem talks about 3 seperate bugs which compounded into what felt like one massive step back.
Here's my breakdown:
Bug 1: They silently downgraded reasoning effort
Claude Code's default reasoning was changed from high to medium. The goal was reducing latency, instead we got worse outputs (first found here).
Bug 2: A caching bug wiped Claude's memory a lot
This one was the most insane. They shipped an 'optimisation' to clear old thinking from idle sessions. This bug caused it to wipe reasoning history for the rest of the session.
Claude would execute a task and forget why it made all decisions.
This is what I reported. Claude Code editing files it hadn't read, fabricating task completions, losing context mid session (This personally also led to Claude Code randomly undoing commits for me 🤦).
Bug 3: A system prompt capped responses at 25 words.
They added this instruction to the system prompt:

After "multiple weeks of internal testing and no regressions". Reverted after quality tanked across both Opus 4.6 and 4.7.
The Community Response Was Brutal
This Reddit thread "Anthropic just published a postmortem explaining exactly why Claude felt dumber for the past month" hit 2.1K likes and 400 comments.
The top comment sums it up perfectly:
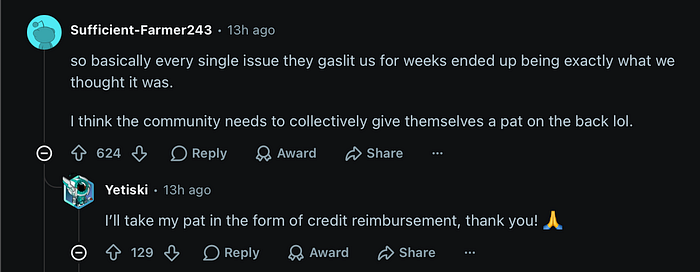
"So basically every single issue they gaslit us for weeks ended up being exactly what we thought it was. I think the community needs to collectively give themselves a pat on the back."
Another great comment:
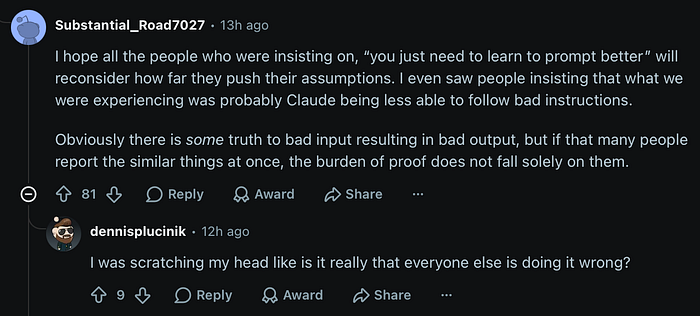
"I hope all the people who were insisting on 'you just need to learn to prompt better' will reconsider how far they push their assumptions."
That hit home for me personally (a few nasty commenters on my posts too).
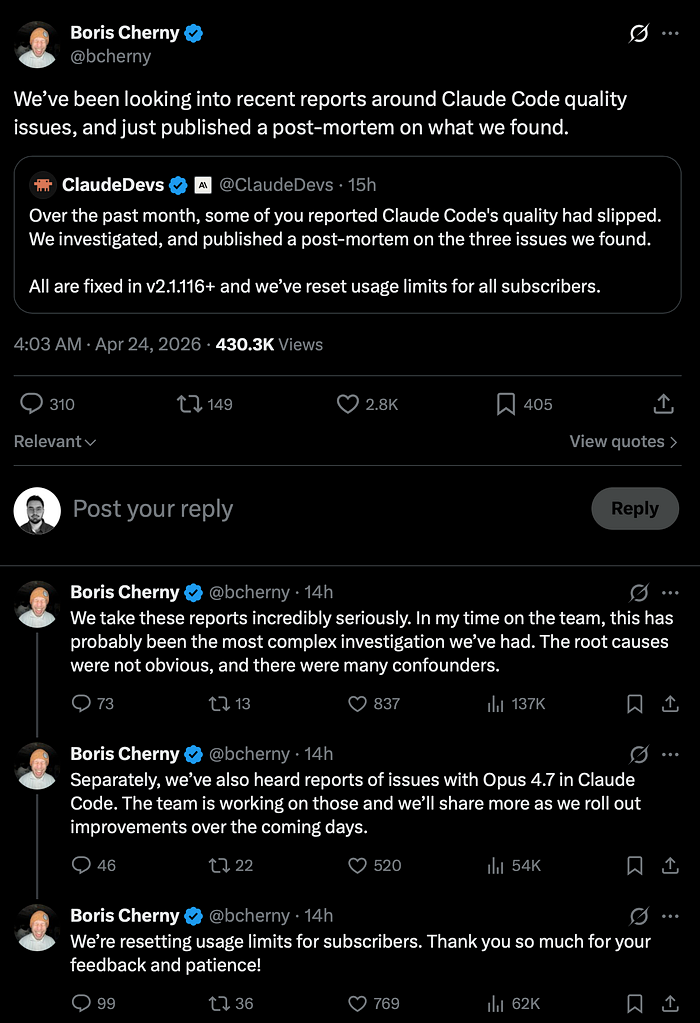
Boris Cherny's Response
Boris tweeted about the fixes confirming the three issues stemmed from the harness and Agent SDK.
He also announced usage limits would be reset for all subscribers.
Remember when I said AMD's Senior AI Director Stella Laurenzo provided 6,852 sessions of proof, well their response? They closed the issue.
I also want to point out Boris Cherny has mentioned Claude Code is fixed, however reports of Opus 4.7 in Claude Code issues are not fully resolved.
The Timing Is Suspicious
The postmortem is dropped on the same day as GPT-5.5, one of OpenAI's biggest releases of the year.
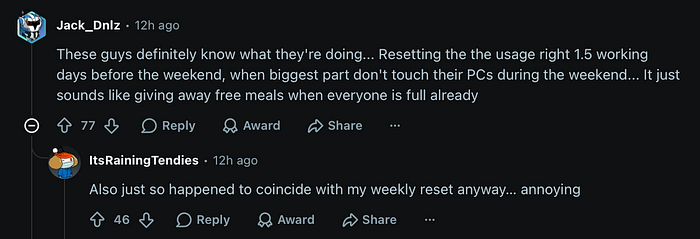
I have to agree with Jack_Dnlz, the usage reset is even more suspect. It dropped 1.5 working days before the weekend. When most developers aren't even at their machines.
"These guys definitely know what they're doing… Resetting the usage right 1.5 working days before the weekend, when biggest part don't touch their PCs during the weekend… It just sounds like giving away free meals when everyone is full already."
The Aftermath
The postmortem is appreciated. Already damage has been done that a blog post doesn't fix.
- Goodwill is gone. For weeks, the community raised alarms. The response was deflection. Now we know they were investigating internally the entire time.
- They tried removing Claude Code from Pro. Two days before the postmortem, on April 21st, Anthropic quietly removed Claude Code from the $20/month Pro tier pricing page. They called it a "2% test on new signups" but the entire website and all support docs were updated.
- AMD already left. Stella Laurenzo's team switched providers weeks ago. 50 agents running complex systems, all moved off Claude Code. Her words are good here:
"6 months ago, Claude stood alone in terms of reasoning quality. Anthropic is far from alone at the capability tier that Opus previously occupied."
- Personal damage. I had so much work undone because of Claude Code wiping memory and choosing to undo my commit history. I'm not exaggerating when I say I almost rage quit.
- Opus 4.7 is still expensive. The new tokenizer uses 1.35x more tokens. Usage is noticeably higher than Opus 4.6. Even with fixes applied.
The Competition Showed Up
While Anthropic was shipping bugs, everyone else has continued shipping.
- GPT-5.5 dropped. OpenAI released their newest frontier model yesterday. Early reports are good. NVIDIA already has 10,000+ employees using it internally with what they're calling "mind-blowing" results.
- Kimi K2.6 went open source. Moonshot AI released a 1T parameter model with 32B active, open weights on Hugging Face. It's scoring ahead of Claude Opus 4.6 and GPT-5.4 on benchmarks including HLE-Full.
- Codex is getting real. Many developers who got burnt by Claude Code have switched to Codex.
- I bought a GPU. The quality of local models has gone up enough and the price we pay for cloud has gone up enough that running local LLMs finally makes economic sense to me.
To Everyone Who Said I Was Overreacting
Do you believe me now?
It came straight from Anthropic. Not just from me, Reddit, X threads, AMD's opened issues. From a published postmortem.
Every single report from the community was valid.
Every single dismissal was wrong.
What You Can Do Right Now
The fixes are live but you need to take action.
The Bare Minimum: Update Claude Code to v2.1.116 or later. The three bugs are patched in this version. Run claude update now.
The Workflow Audit: Try Opus 4.6 vs 4.7 for your workflow. Usage is still higher on 4.7 but with the fixes applied, quality is better than it was. Results will vary. I recommend setting effort to medium and testing both on a real task.
The Pivot: Check out GPT-5.5 in Codex. It's legitimately good. Also worth exploring Kimi K2.6 if you want a good open source option.
What We Can Expect Next
Anthropic seems to be under pressure, everything is pointing to them cost cutting. You can see their IPO preparation.
I use Claude and Claude Code every day. I want it to be the best, however shipping regressions and denying community reports, doesn't earn my trust.
I want to give credit when they have done good, the postmortem was a good step forward.
However I personally feel my subscription is on thin ice with Anthropic and I'm already actively trying alternatives heavily.
I am not affiliated with Anthropic, AMD, OpenAI, Moonshot AI, or anyone else mentioned. All thoughts are my own.
One More Thing
If you liked this piece, you'll like my Substack.
It's where I go deeper. Exclusive Claude Code prompts, CLAUDE.md setups, configurations, real workflows I'm running day to day. The stuff that's too specific for Medium but makes a real difference when the tools you rely on keep changing and breaking.
Built for developers shipping with AI.